The Right Way to Embed an LLM in a Group Chat

In a typical group chat, adding an AI assistant may be occasionally useful at best, and downright annoying at worst. If a user has a question for an AI related to the discussion, it isn’t much more effort to switch to a different app like ChatGPT and, if needed, copy the answer back to the group chat. Having AI embedded into the chat might save a step or two, but at the cost of potentially derailing the existing conversation.
AI gets a bit more useful when you give it access to embedded tools. If your chat supports polls, for example, you could ask the AI to look up potential restaurants for a weekend hangout and create a poll for the group to vote on. If you relied on an external app like ChatGPT to do this research, you’d have to manually set up the poll and copy in the restaurant context, so you’ve just saved yourself a lot of time.
Where AI-assisted group chat becomes incredibly useful is in the context of a purpose-built chat embedded in a larger application. Our use case is a travel planning app, TripJam, where travel groups collaborate on their itinerary, to-dos, budget, and more.
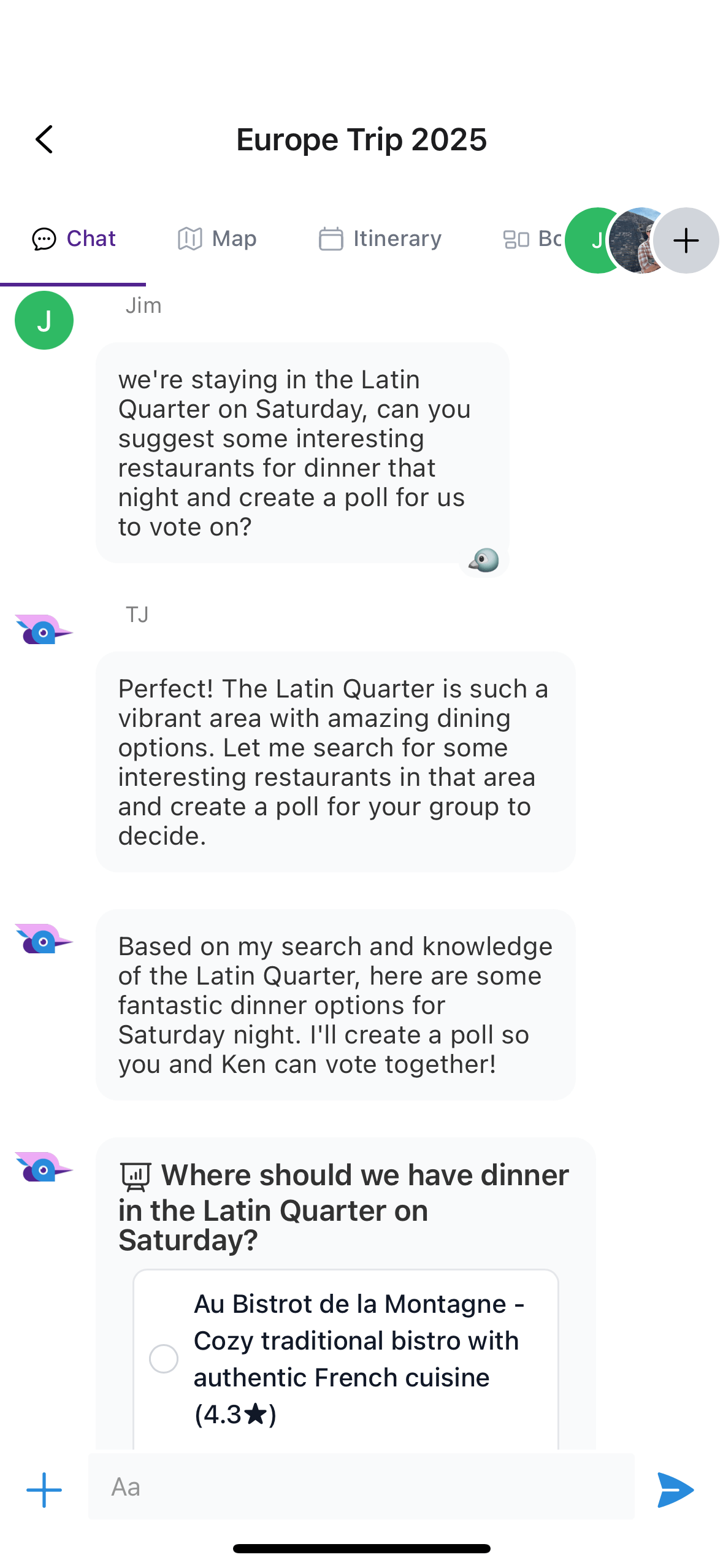
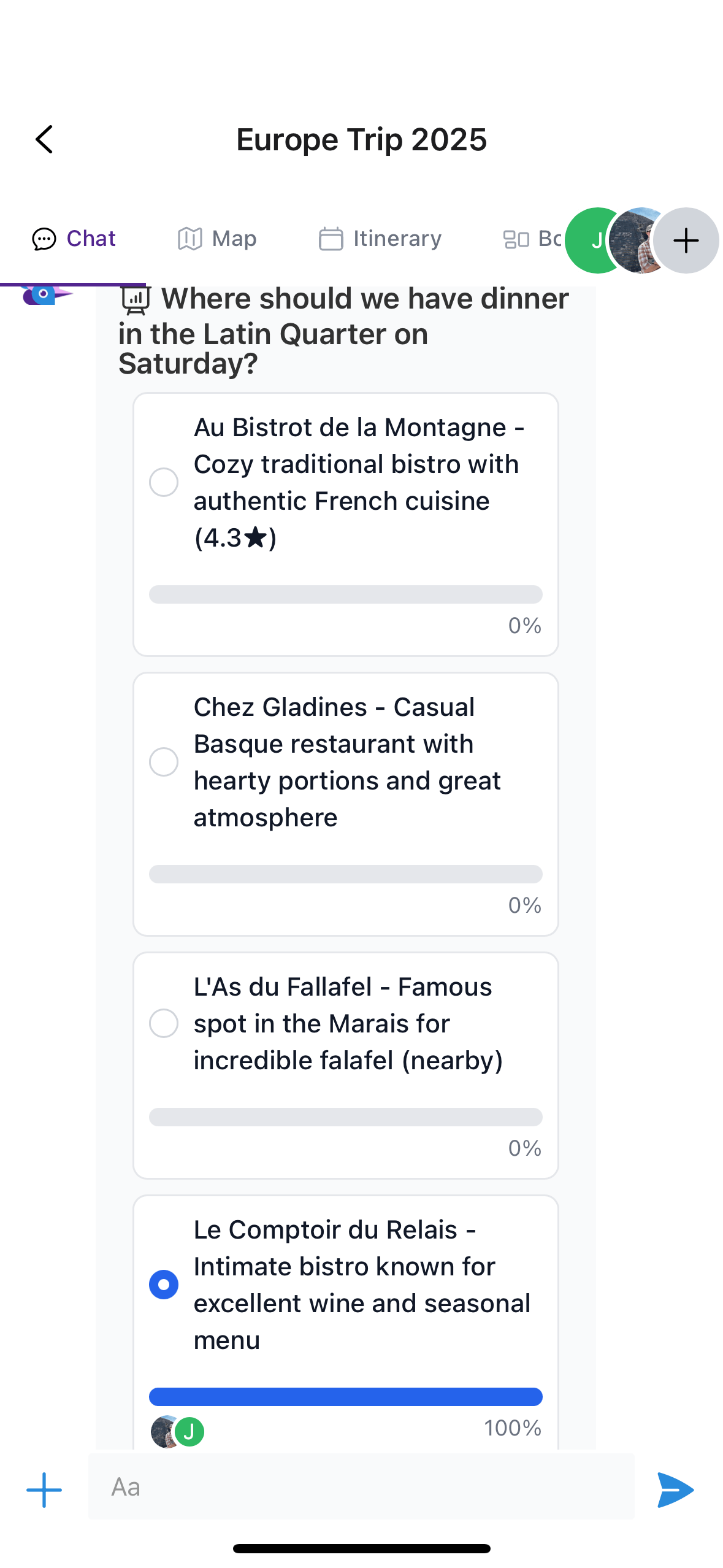
TJ searches Google for restaurant ideas and adds them as poll options for the group to vote on.
What’s the Problem?
In an app like ChatGPT, the basic intent of each message is clear: the user is addressing the AI and expects a response. In the context of a group chat, however, an AI assistant’s job is much more difficult: the average message is more likely than not directed at another user, so the AI’s goal should be to respond only when needed and otherwise be unobtrusive.
In an app like TripJam, the assistant is only useful to the extent that it can perform the action asked of it. This action may be as simple as summarizing a potential vacation location, or a complex multi-step process such a looking up top restaurants in an area, moving the map to display them next to the other itinerary locations, and adding them to the itinerary itself. Interaction with the assistant should feel like time-saving magic, and as soon as that usefulness breaks down, the user will be much less likely to interact with the AI in the future.
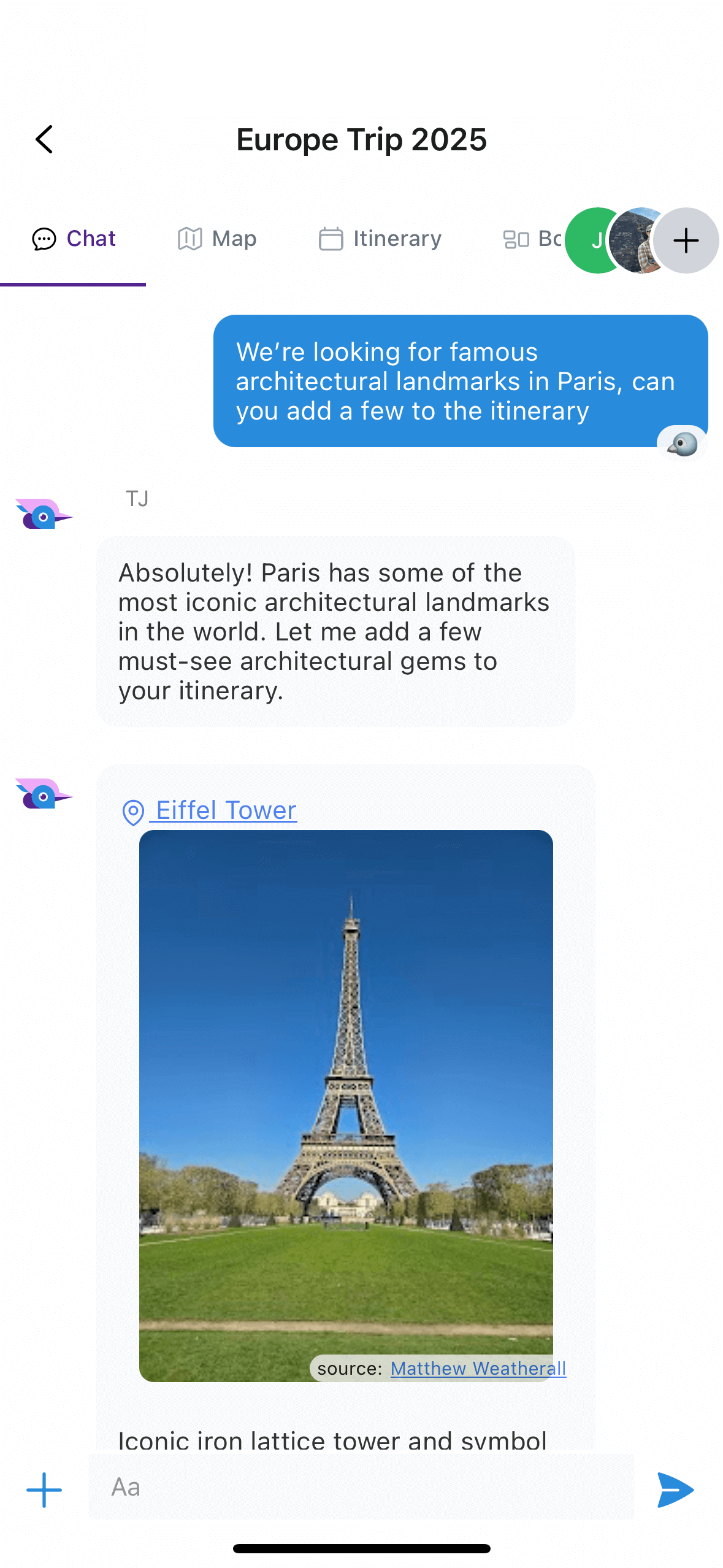
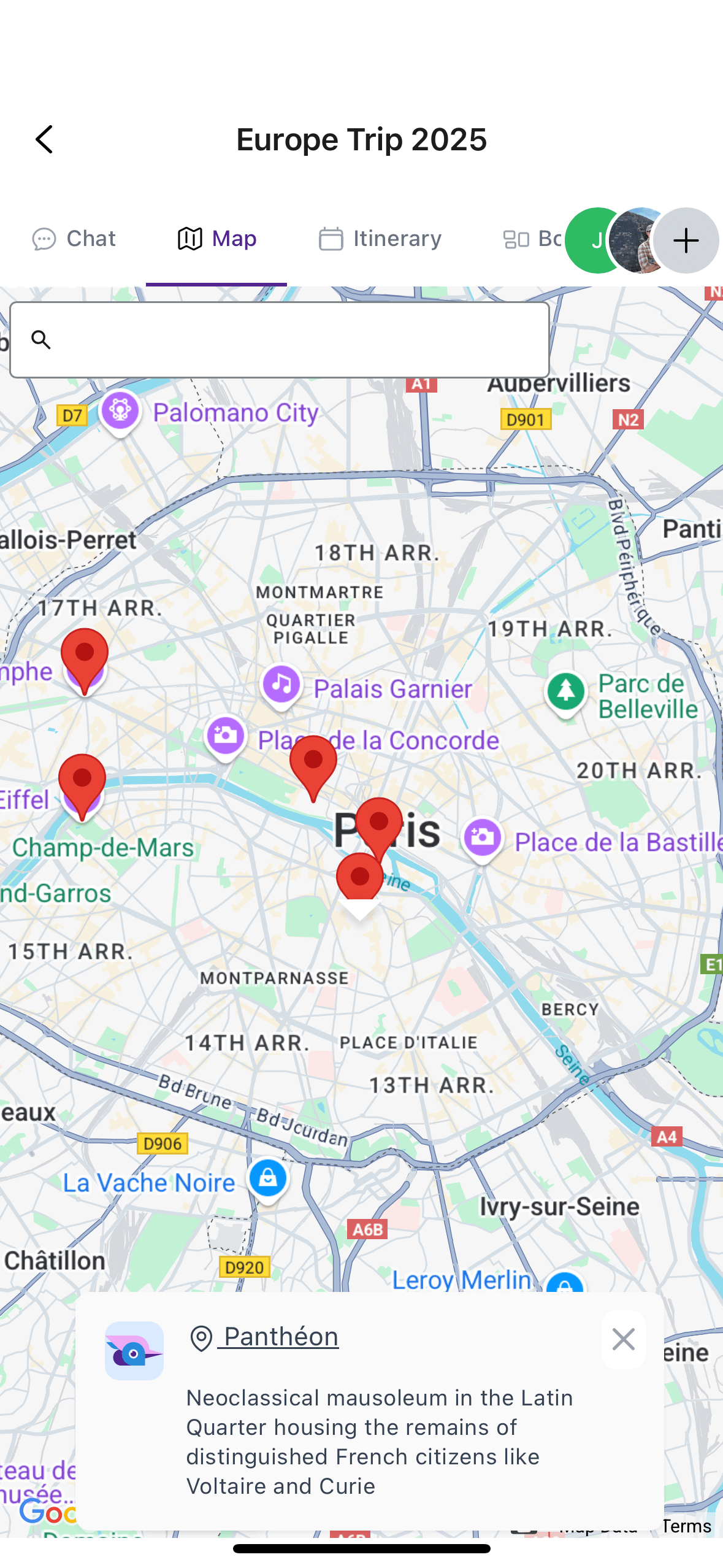
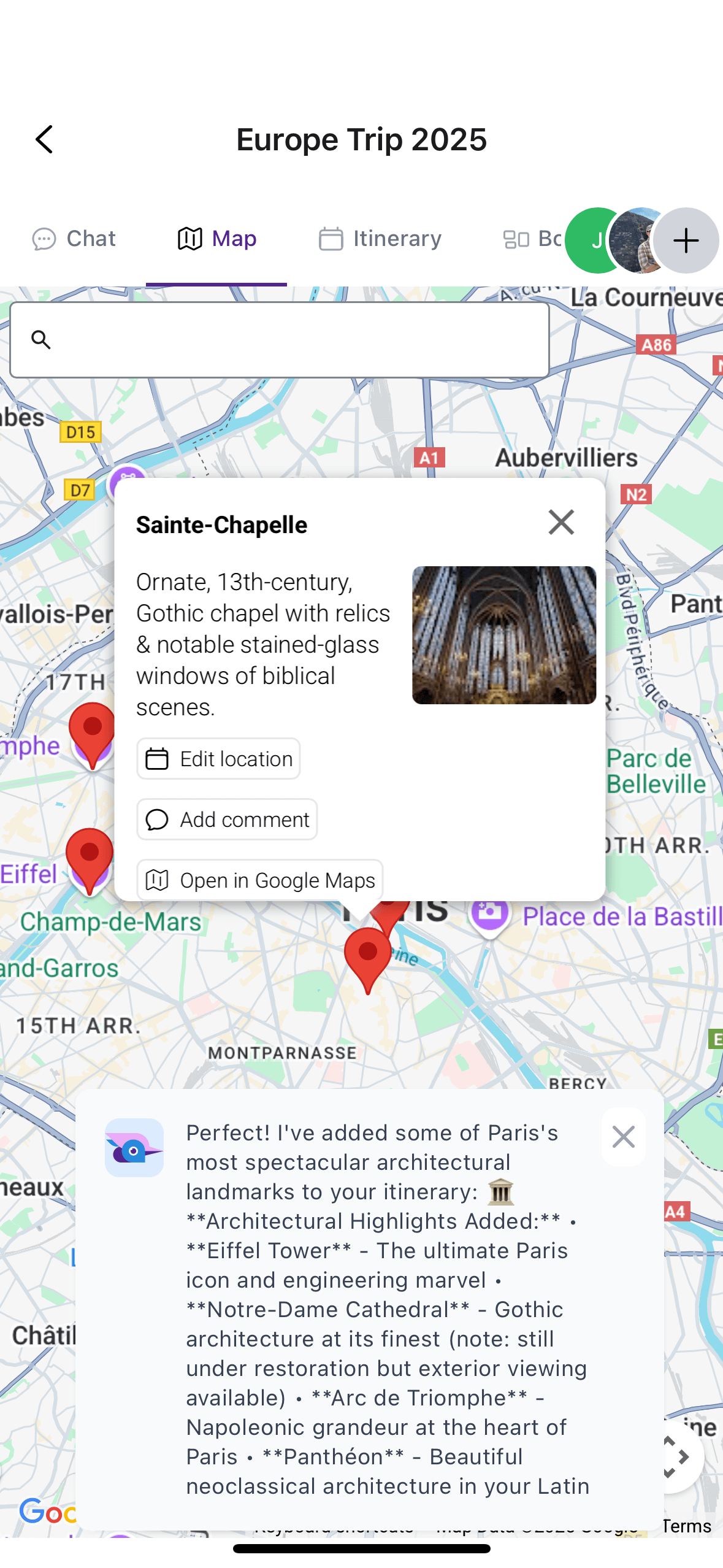
TJ can add locations to the itinerary, interact with the map, and highlight the location it's referring to.
Tool Use
The AI assistant should have an extensive list of tools available to interact with your system. A modern LLM can chain these function calls together in ways that feel seamless and save users time and effort.
Available Functions
- add_location
- Description: Add an event and corresponding location to the trip’s itinerary. Location editing and deletion also supported.
- Arguments: name, description, date_time, lat, lng
- center_map
- Description: Move the map view to the coordinates specified.
- Arguments: lat, lng, zoom
- search_places
- Description: Search for recommended locations in an area using the Google Places API.
- Arguments: lat, lng, search_term, radius
- add_todo
- Description: Add a todo item to the trip’s todo list.
- Arguments: title, description, assigned_to_id
- add_poll
- Description: Create a poll to help the group make decisions.
- Arguments: name, options
System Prompt
In a purpose-built group chat app, the system prompt can provide valuable context about app state and user data.
Aside from guiding how the AI should behave, TripJam injects trip-specific info directly into the prompt, like the itinerary, list of users, and the requesting user’s name and timezone. Compared to requiring the AI to fetch this context through function calls, injecting it ensures the AI always has the necessary info, especially when adding a location to the itinerary.
Querying the AI
How do we parse user intent in regards to the AI assistant? For v1 we opted for a conservative approach: the AI will only respond when the user queries it directly, either by prefixing a message with the assistant’s name (“TJ, what are some popular restaurants in Manhattan?”) or by flagging a chat message to be sent to the AI after the fact. In either case, the entire group sees the message that’s sent to the AI as well as its response.
We plan to enhance this behavior in a couple ways. First, our current approach requires the users to already be aware of the AI features available to them in the group chat. Instead, we could attempt to infer AI intent based on the contents of the chat, and prompt users to request AI assistance. We need to be careful here to avoid annoying our users (think Clippy).
Another planned enhancement: not every message sent to the AI needs to be visible to the entire group. For example, if a user requests that the AI perform a simple action such as adding a location, only the result of that action needs to be visible to the group (the actual location added), not the entire AI conversation. This is reminiscent of more traditional actions in group chat applications like slash commands in Slack.
Context
Group chats can become very large, so it quickly becomes unfeasible to send the entire chat history to the AI assistant every time it’s queried. We again take a conservative approach to this problem by simply sending the last n=15 messages to the AI whenever it’s queried. We’ve found this approach to work well enough, since typically that’s more than enough context for the agent to understand what is being asked of it.
But this approach is also ripe for enhancement. One obvious improvement would be to allow the AI to load more messages if it deems that it’s needed to ascertain the context (maybe in 15-message increments). Another would be to expose a search function to the AI agent, essentially enabling retrieval-augmented generation.
Architecture
What happens if multiple users are querying the AI agent at the same time? How do we ensure the agents don’t step on each others’ toes? To manage this we spin up a pool of AI workers when the application is started. Each worker is assigned an incrementing number, and any request to the AI gets sent to the worker corresponding to the group’s ID modulo the number of workers. Basically we just process the requests one at a time for any given group.
Privacy
We value our users’ privacy immensely - we use OpenRouter’s API and Anthropic’s models to power TripJam. While their respective privacy and data retention policies are documented, leveraging a publicly hosted LLM always comes with an amount of tradeoff between privacy and utility. We would love to allow privately-hosted or custom LLM integrations in the future.
Future
Aside from the future enhancements already discussed, Model Context Protocol is top of mind. Exposing TripJam as an MCP server would have clear benefits to our users, for example if they’d rather interact with their trip and itinerary through a separate client like ChatGPT. Similarly, support for MCP clients within the TripJam application would allow power users to augment their group chat experience with additional tools.
Interested in trying it out for yourself? Visit TripJam to learn more and get started. Have ideas or feedback regarding this post? Contact us!